SREの林 aka もりはやです。
タイトルの通りですし、PostgreSQL界隈の皆さんには当たり前のことですが”失敗事例の共有はいくらあってもいいはず”の気持ちで本記事を書いています。*1
TL;DR
何よりもまず、アップグレードガイドを読みましょう!!!!!! AWS公式ドキュメント _ Amazon Aurora PostgreSQL DB クラスターのアップグレード
本記事の要約としてシンプルに書くと以下の流れでした。
- Amazon Aurora PostgreSQLのバージョンを15.5 -> 16.1 へアップグレードしました
- AP側はエラーが出てもかまないので起動し続けた状態
- アップグレード完了後からCPU張り付き
- EXPLAINで調査して怪しいところを確認
- Slow queryで出ていたテーブルに
ANALYZE <TABLE>を実施して復旧 - 落ち着いてからDB全体に
ANALYZE VERBOSを実施して完全復旧
詳細
最新バージョンでアプリを移行した矢先にAurora PostgreSQLのv16.1対応が発表
先日のブログで記載しましたが「現時点で最新バージョンのAurora PostgreSQL 15.5」が最新ではなくなるリリースが2024-01-31にAWSさんより発表されました。Aurora PostgreSQLの16.1への対応です。
これを受けて、意気揚々とAurora PostgreSQLのバージョンアップを実施
まだ仮リリース中のシステムであるため、今のうちに最新化しようと考えネットワーク担当のT氏に打診すると、二つ返事でOKをいただきました。*2

前提として当社はIaCを推進しております。今回対象のZabbixのシステムも、AuroraはもちろんEC2はPacker内でAnsibleをCallしてAMIを作成し、各種AWSリソースの全てをTerraformで管理しています。しかし、今回のDBのアップグレードのような精神的にも影響的にも重い作業はあえてWebコンソールで実施しました。
これは過去経験からいってWebコンソールならではの警告やウィザードに助けられることが少なくないからです。
そんなわけでポチッとやりました。

またしてもCPU高騰、そして504多発
ダウンタイム時間は想定よりも短く15分程度で終わりました。
ダウンタイム計測用に回しておいた psql 定期実行のスクリプトがアップグレード後に再び通るようになったことを確認した私は、特に動作確認もせず連続MTGに突入しました。
思い返せば慢心で、この時動作確認をすれば気づけていた問題がMTG中に発生していました。それが以下のPerformance Insightのグラフに現れています。

バージョンアップ完了直後から、グラフが一気に跳ね上がっていることがわかります。しかも、先日のCPU高騰の状況で高かった IO:DataFileRead(水色) は今回は目だたず、高騰要因としては CPU(緑色) であることが見えています。
短絡的な自分は「もしかしてPostgreSQLまたはAuroraのバグ的な何かを引いてしまったのか...」と考えました。
調査開始
いつまでも短絡的ではいられないため、気持ちを切り替えて調査を開始します。
Peformance Insightの結果から、DBがボトルネックになっていることはわかっていたため、DBの何が問題かを切り分ける動きをしました。
ZabbixにはSlow queryを出力する機能がデフォルトである
当初はPerformance Insightの TOP SQL を眺めましたが、いまいち法則性が見えませんでした。
次に、Zabbixのログを調査することにしました。
声を大にして伝えたいですが、Zabbixは成熟したOSSの一つで、DBへのSlow queryをログに記録する機能がデフォルトで有効になっています。ログを見ると以下のような状況でした。
抜粋すると以下のようなSlow queryが多発しており、パッと見では脈絡がなくてまさにスロークエリーパラダイス、 ”Like 'Slow query' paradise. What is this one?” な状況でした。*3
663:20240201:175233.629 slow query: 7.018993 sec, "select i.itemid,i.hostid,i.templateid from items i inner join hosts h on i.hostid=h.hostid where h.status=3" 999:20240201:175239.932 slow query: 3.304854 sec, "select distinct t.triggerid,t.templateid,i.hostid from items i,functions f,triggers t where i.itemid=f.itemid and f.triggerid=t.templateid and t.triggerid=148316" 663:20240201:175853.831 slow query: 3.644245 sec, "select i.itemid,i.hostid,i.status,i.type,i.value_type,i.key_,i.snmp_oid,i.ipmi_sensor,i.delay,i.trapper_hosts,i.logtimefmt,i.params,ir.state,i.authtype,i.username,i.password,i.publickey,i.privatekey,i.flags,i.interfaceid,ir.lastlogsize,ir.mtime,i.history,i.trends,i.inventory_link,i.valuemapid,i.units,ir.error,i.jmx_endpoint,i.master_itemid,i.timeout,i.url,i.query_fields,i.posts,i.status_codes,i.follow_redirects,i.post_type,i.http_proxy,i.headers,i.retrieve_mode,i.request_method,i.output_format,i.ssl_cert_file,i.ssl_key_file,i.ssl_key_password,i.verify_peer,i.verify_host,i.allow_traps,i.templateid,null from items i inner join hosts h on i.hostid=h.hostid join item_rtdata ir on i.itemid=ir.itemid where (h.status=0 or h.status=1) and (i.flags=0 or i.flags=1 or i.flags=4)"
クエリチューニングするならEXPLAINを使う
ZabbixのSlow queryログによって正確なクエリを入手した後は、EXPLAINの出番です。*4
EXPLAINには実行を伴わない通常の EXPLAIN と、実行をしてより正確な結果を出す EXPLAIN ANALYZE があります。
手始めにEXPLAINを実行しました。
zabbix=> explain select distinct t.triggerid,t.templateid,i.hostid from items i,functions f,triggers t where i.itemid=f.itemid and f.triggerid=t.templateid and t.triggerid=148294
zabbix-> ;
QUERY PLAN
---------------------------------------------------------------------------------------------------------
Unique (cost=607.97..608.23 rows=1 width=24)
-> Sort (cost=607.97..608.05 rows=35 width=24)
Sort Key: t.templateid, i.hostid
-> Nested Loop (cost=18.60..607.07 rows=35 width=24)
Join Filter: (i.itemid = f.itemid)
-> Index Scan using items_pkey on items i (cost=0.38..8.39 rows=1 width=16)
-> Nested Loop (cost=18.23..598.24 rows=35 width=24)
-> Index Scan using triggers_pkey on triggers t (cost=0.42..8.44 rows=1 width=16)
Index Cond: (triggerid = 148294)
-> Bitmap Heap Scan on functions f (cost=17.81..588.01 rows=180 width=16)
Recheck Cond: (triggerid = t.templateid)
-> Bitmap Index Scan on functions_1 (cost=0.00..17.77 rows=180 width=0)
Index Cond: (triggerid = t.templateid)
(13 rows)
zabbix=>
この結果をどう読むかはさまざまな流派や勘所があると考えますが、シンプルにコスト部分をみると cost=607.97..608.23 となっており、決して高い数字ではないと判断しました。実際には ANALYZE による改善後と比べると高いのですが、悪化前を知らないと判断が難しいところです。
続いて EXPLAIN ANALYZE を実行した結果がこちらです。
zabbix=> explain analyze select distinct t.triggerid,t.templateid,i.hostid from items i,functions f,triggers t where i.itemid=f.itemid and f.triggerid=t.templateid and t.triggerid=148294
;
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------------------------------------------
Unique (cost=607.97..608.23 rows=1 width=24) (actual time=4794.897..4794.903 rows=1 loops=1)
-> Sort (cost=607.97..608.06 rows=35 width=24) (actual time=4794.896..4794.898 rows=3 loops=1)
Sort Key: t.templateid, i.hostid
Sort Method: quicksort Memory: 25kB
-> Nested Loop (cost=18.61..607.07 rows=35 width=24) (actual time=339.023..4794.877 rows=3 loops=1)
Join Filter: (i.itemid = f.itemid)
Rows Removed by Join Filter: 597792
-> Index Scan using items_pkey on items i (cost=0.38..8.39 rows=1 width=16) (actual time=0.021..335.882 rows=199265 loops=1)
-> Nested Loop (cost=18.23..598.24 rows=35 width=24) (actual time=0.018..0.021 rows=3 loops=199265)
-> Index Scan using triggers_pkey on triggers t (cost=0.42..8.44 rows=1 width=16) (actual time=0.006..0.006 rows=1 loops=199265)
Index Cond: (triggerid = 148294)
-> Bitmap Heap Scan on functions f (cost=17.81..588.01 rows=180 width=16) (actual time=0.011..0.013 rows=3 loops=199265)
Recheck Cond: (triggerid = t.templateid)
Heap Blocks: exact=398530
-> Bitmap Index Scan on functions_1 (cost=0.00..17.77 rows=180 width=0) (actual time=0.006..0.006 rows=3 loops=199265)
Index Cond: (triggerid = t.templateid)
Planning Time: 0.510 ms
Execution Time: 4794.947 ms
(18 rows)
zabbix=>
1行目からおかしいことがわかります。
cost=607.97..608.23 rows=1 width=24) (actual time=4794.897..4794.903 rows=1 loops=1)
Actual time が 4794.897(4.7Sec)と高い数字となっており、これは何かおかしいと考え読み進めます。
疑い出すとどこもかしこも怪しく見えますが、最下段の処理としては最初に行われた部分で、Bitmap Index Scan を利用して loopsがやたらに多いことがわかりました。
-> Bitmap Index Scan on functions_1 (cost=0.00..17.77 rows=180 width=0) (actual time=0.006..0.006 rows=3 loops=199265)
ここまで来て「あれ、これもしかして統計情報の更新が必要では...?」と思い当たります。
ANALYZEを実行することで解決
統計情報が怪しいとあたりがつけば答えはすぐそこでした。
PostgreSQLで統計情報を更新するには ANALYZE コマンドを利用します。
PostgreSQL 15.4文書 - SQLコマンド - ANALYZE より引用
ANALYZEはデータベース内のテーブルの内容に関する統計情報を収集し、その結果をpg_statisticシステムカタログに保存します。 問い合わせプランナが最も効率の良い問い合わせの実行計画を決定する際、この統計情報が使用されます。
後はSlow queryで表示されていた各テーブルに対して ANALYZE <TABLE> を実行していきます。いきなり ANALYZE VERBOS でDB全体に実行するのも状況によってはありですが、コマンド実行に時間がかかる場合がありますし、障害復旧の切り分けとして難しくなる点からまずはTABLE指定の ANALYZE を選んでいます。
そして以下を実行しました。
zabbix=> analyze functions; ANALYZE zabbix=>
確認のために再び EXPLAIN ANALYZE を実行したところ、見違えるように改善していました。
zabbix=> explain analyze select distinct t.triggerid,t.templateid,i.hostid from items i,functions f,triggers t where i.itemid=f.itemid and f.triggerid=t.templateid and t.triggerid=148294
;
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------------------------------------
Unique (cost=21.07..21.08 rows=1 width=24) (actual time=0.045..0.048 rows=1 loops=1)
-> Sort (cost=21.07..21.07 rows=1 width=24) (actual time=0.044..0.045 rows=3 loops=1)
Sort Key: t.templateid, i.hostid
Sort Method: quicksort Memory: 25kB
-> Nested Loop (cost=1.21..21.06 rows=1 width=24) (actual time=0.029..0.038 rows=3 loops=1)
-> Nested Loop (cost=0.84..19.38 rows=1 width=24) (actual time=0.018..0.021 rows=3 loops=1)
-> Index Scan using triggers_pkey on triggers t (cost=0.42..8.44 rows=1 width=16) (actual time=0.010..0.010 rows=1 loops=1)
Index Cond: (triggerid = 148294)
-> Index Scan using functions_1 on functions f (cost=0.42..10.91 rows=3 width=16) (actual time=0.007..0.009 rows=3 loops=1)
Index Cond: (triggerid = t.templateid)
-> Index Scan using items_pkey on items i (cost=0.38..1.02 rows=1 width=16) (actual time=0.005..0.005 rows=1 loops=3)
Index Cond: (itemid = f.itemid)
Planning Time: 0.590 ms
Execution Time: 0.078 ms
(14 rows)
zabbix=>
わかりやすく比較のために並べると、最上段の結果は以下。
- ANALYZE前
Unique (cost=607.97..608.23 rows=1 width=24) (actual time=4794.897..4794.903 rows=1 loops=1)
- ANALYZE後
Unique (cost=21.07..21.08 rows=1 width=24) (actual time=0.045..0.048 rows=1 loops=1)
怪しいと睨んだ最下段の結果は以下。
- ANALYZE前
Bitmap Index Scan on functions_1 (cost=0.00..17.77 rows=180 width=0) (actual time=0.006..0.006 rows=3 loops=199265)
- ANALYZE後
Index Scan using functions_1 on functions f (cost=0.42..10.91 rows=3 width=16) (actual time=0.007..0.009 rows=3 loops=1)
どちらも劇的にCostもActual timeも下がっていることが確認できました。
こうなれば後は表示されたSlow queryのFROM句のTABLEに対して、見つけ次第 ANALYZE <TABLE> を実行していくのみです。
一通りSlow queryを潰した後でPerformance Insightに戻ると、見違えるように負荷の下がったグラフを確認できました。

仕上げのDB全体へのANALYZE
この時点でZabbixとしては安定を取り戻していましたが、油断してはいけません。*5
Slow queryとしてわかりやすく出てきたTABLE以外にも ANALYZE をかける必要があります。潜在的に遅くなる要因を残すことになるためです。そこで行うのがTABLEパラメータ無しの ANALYZE VERBOS です。
PostgreSQL 15.4文書 - SQLコマンド - ANALYZE より引用
table_and_columnsリストがない場合、ANALYZEは現在のデータベース内で現在のユーザが解析する権限のあるすべてのテーブルとマテリアライズドビューを処理します。 リストがある場合、ANALYZEは指定されたテーブルのみを処理します。 さらにテーブルの列名のリストを与え、その列の統計情報のみを収集することも可能です。
事実として ANALYZE <TABLE> 実行後にも動作確認の中で多少のCPU上昇が見受けられましたが ANALYZE VERBOS による全体の統計情報更新後は、極めて安定した状況となりました。
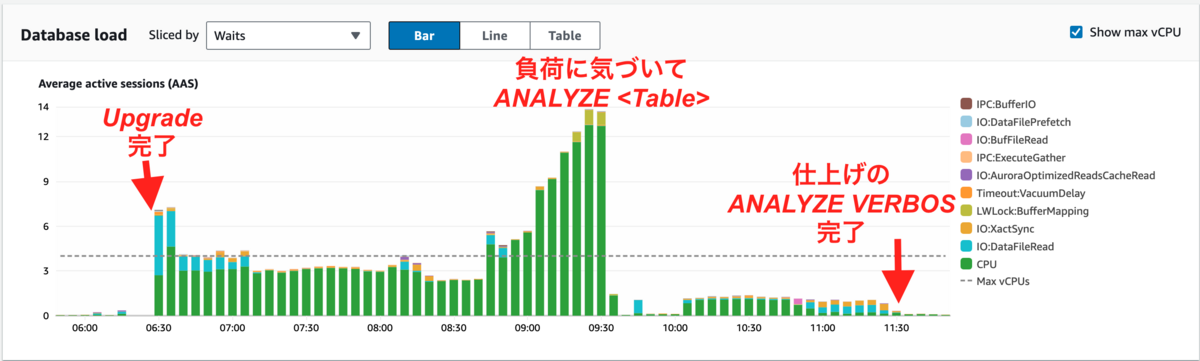
今回述べた一連の流れを1つのグラフとしたものが以下となります。
- Aurora VUP完了とともにCPUが張り付き始め
ANALYZE <TABLE>実行によるテーブルの統計情報更新によって負荷が下がりANALYZE VERBOSによる全体の統計情報更新によって安定
といった流れが見えるでしょうか。
まとめ
こうしてPostgreSQLのバージョンアップグレードをして想定外のCPU高騰を経験した経緯を記載しましたが、お伝えしたいのは1つだけです。
「何よりもアップグレードガイドを読みましょう、話はそれからだ...」
今回トラブルシューティングの上でたどり着いた ANALYZE について、明確にアップグレードガイドに記載があります。
AWS公式ドキュメント _ Amazon Aurora PostgreSQL DB クラスターのアップグレード より引用します。
メジャーバージョンアップグレードが完了したら、以下のことをお勧めします。
ANALYZE 操作を実行して pg_statistic テーブルを更新します。これは、すべての PostgreSQL DB インスタンスのすべてのデータベースに対して行う必要があります。Optimizer の統計情報はメジャーバージョンのアップグレード中には転送されないため、パフォーマンスの問題を回避するためにすべての統計情報を再生成する必要があります。次のようにパラメータを指定せずにコマンドを実行して、現在のデータベース内のすべての標準テーブルの統計情報を生成します。
そして、引用した ANALYZE 以外のアップグレード時の気をつけるべきポイントが丁寧に記載されています。
今回私は、対象のAuroraが仮リリース中のシステムのDBである慢心から「えいや」でアップグレードを実施しましたが、公式のアップグレードガイドにもあるように 「本番環境でアップグレードする前に、パフォーマンスをテストして確認することをお勧めします」
