SREの高木です。
Amazon Elastic Kubernetes Service(以下EKS)において、Node障害に備えてPodの分散配置を実現しました。
本記事でその事例をご紹介します。
背景
弊社ではコーポレートサイトや複数のオウンドメディアをEKS上に構築しています。*1
これまでPodをどのNodeに配置するかを特に制御していませんでしたが、ある時Node障害が発生し、そのNode上に偏ってPodが起動していたためWebサイトが閲覧不可になるという障害が起きてしまいました。
その対策として、特定のNodeに偏らないようPodを分散配置する方法を調査・検証することにしました。
TL;DR
- 3つの機能を使います
- Pod Topology Spread Constraints
- Descheduler
- PodDisruptionBudget
- 各機能を組み合わせることで、サービスダウンを回避しながらPodの分散配置を実現します
- Podの配置戦略を立てる
- 配置戦略を満たすように定期的にPodの再スケジューリングを行う
- 再スケジューリング実行時にサービス稼働を維持するためにPodの最小有効数や最大無効数を定義する
環境
本記事で使用している環境は以下の通りです。
- EKS バージョン1.21
- EKSのNodeとしてEC2を使用
Podの分散配置を実現するために使用する機能
Pod Topology Spread Constraints
ホスト/リージョン/ゾーンなどの"topology"を意識してPodを分散配置する機能です。
Pod Topology Spread Constraintsの設定方法の詳細は公式ドキュメントを参照してください。
Descheduler
Pod Topology Spread Constraintsの戦略に従ってPodを分散してくれるのは、Podを新規作成したときのみです。
例えば以下のようなとき、他のNodeに再配置したPodの配置方法がPod Topology Spread Constraintsの戦略に従ったものではなくなる可能性があります。
- Node障害でPodがevictされたとき
- ClusterAutoscalerやKarpenterなどのAutoscalerによってNodeがスケールインしてPodがevictされたとき
これを解決するために、Deschedulerを使用して定期的にPodの再スケジューリングを行います。
Deschedulerの使用方法の詳細はDeschedulerのGitHubリポジトリを参照してください。
Descheduler利用時の注意事項
Kubernetesのバージョンによって使用できるDeschedulerのバージョンが異なります。
Kubernetesのバージョンに適合するDeschedulerイメージを使用してください。
参考:https://github.com/kubernetes-sigs/descheduler#compatibility-matrix
Deschedulerは最新の3つのKubernetesバージョンまでが動作確認済みとなっています。
例えばDeschedulerのバージョンがv0.25の場合、Kubernetes 1.25,1.24,1.23で動作確認が行われています。
また、Descheduler v0.25.0未満を使う場合はRBACが最新と異なります。
参考:v0.25.0のcommit
PodDisruptionBudget (PDB)
Podのevict時に有効状態にしておく最小のPodの数/割合や、無効状態を許容する最大のPodの数/割合を指定します。
DeschedulerやNodeのdrainの実行により意図せずPodが全て落ちてサービスダウンが発生することを防ぐため、PodDisruptionBudgetを設定します。
設定方法の詳細は公式ドキュメントを参照してください。
検証
各機能を実装した際の動作検証を行います。
1. Podを起動したとき、Pod Topology Spread Constraintsの戦略に従ってPodが別々のNodeに配置されるか?
Deploymentを用意して検証します。
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-deployment
spec:
(略)
template:
metadata:
labels:
name: my-deployment
app: my-deployment
spec:
(略)
topologySpreadConstraints:
- maxSkew: 1 # topologyKey間で許容するPod数の差異
topologyKey: kubernetes.io/hostname # Node群を定義するために使用する、NodeのLabel。LabelのValueが同じものをひとまとまりのNode群として扱う
whenUnsatisfiable: ScheduleAnyway # 制約を満たせない場合はSkewを最小化するNodeに優先的にスケジュールする
labelSelector:
matchLabels:
app: my-deployment # app:my-deployment のlabelが付いているPodが対象
上記の記述の場合、「各Nodeで起動する、app: my-deploymentのLabelが付いているPodの数の差を1まで許容する。この制約を満たせない場合、Skew(各topology間のPod数の差異)が最小になるNodeに優先的にPodをスケジュールする」となります。
maxSkewは、topologyKey間で許容するPod数の差異です。
topologyKeyにはNodeのLabelを指定します。
NodeのLabelは以下のコマンドで確認できます。
$ kubectl get node -o json | jq ".items[] | .metadata.labels"
EKSでNodeにEC2を使用している場合はインスタンスタイプやリージョンやアベイラビリティゾーンのLabelが付与されています。
{
"beta.kubernetes.io/arch": "amd64",
"beta.kubernetes.io/instance-type": "m5.large",
"beta.kubernetes.io/os": "linux",
"failure-domain.beta.kubernetes.io/region": "ap-northeast-1",
"failure-domain.beta.kubernetes.io/zone": "ap-northeast-1d",
"k8s.io/cloud-provider-aws": "b1c0c199b783b8879f261ee4adaf366b",
"kubernetes.io/arch": "amd64",
"kubernetes.io/hostname": "ip-10-2-23-157.ap-northeast-1.compute.internal",
"kubernetes.io/os": "linux",
"node.kubernetes.io/instance-type": "m5.large",
"topology.kubernetes.io/region": "ap-northeast-1",
"topology.kubernetes.io/zone": "ap-northeast-1d"
}
whenUnsatisfiableには、topologySpreadConstraintsで定義した制約を満たせる配置先Nodeが存在しない場合の挙動を定義します。
DoNotScheduleとScheduleAnywayの2種類あります。
DoNotScheduleは「制約を満たせない場合Podを起動しない」設定です。
DoNotScheduleを指定すると意図せずPodが起動しないリスクがあるため、制約を満たさないなら絶対にPodを起動させたくないとき以外は使用しない方がいいと思います。*2
例えば下図のような状態の場合、NodeAにPod5を配置するとNodeBおよびNodeCとのPod数の差が2になりmaxSkew: 1に違反するため、Pod5をNodeBかNodeCに配置します。
whenUnsatisfiableがDoNotScheduleなら、必ずNodeBかNodeCに配置します。
whenUnsatisfiableがScheduleAnywayなら、できる限りNodeBかNodeCに配置しますが、NodeBとNodeCにPod5を起動するリソースの余裕が無いなど何らかの理由で不可能ならNodeAに配置します。
NodeBとNodeCのどちらに配置するかはkube-schedulerに依存します。
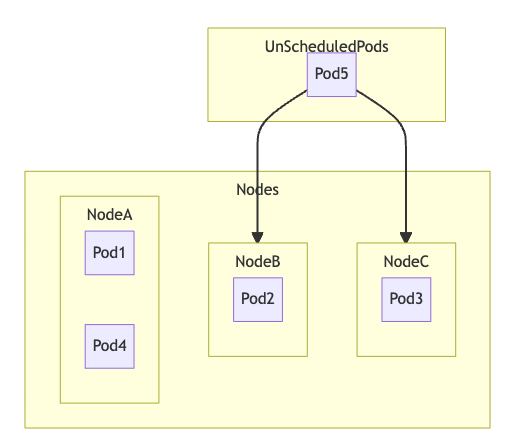
Nodeを3台用意し、Labelがapp: my-deploymentのPodを1台ずつ増やしていきます。
$ kubectl get node NAME STATUS ROLES AGE VERSION ip-10-0-21-33.ap-northeast-1.compute.internal Ready <none> 169d v1.21.5-eks-9017834 ip-10-0-22-75.ap-northeast-1.compute.internal Ready <none> 18d v1.21.14-eks-ba74326 ip-10-0-23-169.ap-northeast-1.compute.internal Ready <none> 169d v1.21.5-eks-9017834
1つ目のPodをapplyします。
$ kubectl get pod -n my-namespace -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES sre-external-dns-6df9778f89-7r9pg 1/1 Running 0 75s 10.0.21.169 ip-10-0-21-33.ap-northeast-1.compute.internal <none> <none> sre-my-deployment-6f5c64cd65-nvqrw 1/1 Running 0 75s 10.0.22.96 ip-10-0-22-75.ap-northeast-1.compute.internal <none> <none>
2つ目のPodをapplyします。
$ kubectl get pod -n my-namespace -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES sre-external-dns-6df9778f89-7r9pg 1/1 Running 0 6m58s 10.0.21.169 ip-10-0-21-33.ap-northeast-1.compute.internal <none> <none> sre-my-deployment-6f5c64cd65-9wdw6 1/1 Running 0 4m24s 10.0.21.247 ip-10-0-21-33.ap-northeast-1.compute.internal <none> <none> sre-my-deployment-6f5c64cd65-nvqrw 1/1 Running 0 6m58s 10.0.22.96 ip-10-0-22-75.ap-northeast-1.compute.internal <none> <none>
3つ目のPodをapplyします。
whenUnsatisfiable: ScheduleAnywayとしているため、Nodeが分散されずに偏りました。
$ kubectl get pod -n my-namespace -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES sre-external-dns-6df9778f89-7r9pg 1/1 Running 0 8m27s 10.0.21.169 ip-10-0-21-33.ap-northeast-1.compute.internal <none> <none> sre-my-deployment-6f5c64cd65-fvtjj 1/1 Running 0 22s 10.0.22.33 ip-10-0-22-75.ap-northeast-1.compute.internal <none> <none> sre-my-deployment-6f5c64cd65-nvqrw 1/1 Running 0 8m27s 10.0.22.96 ip-10-0-22-75.ap-northeast-1.compute.internal <none> <none> sre-my-deployment-6f5c64cd65-sqj9f 1/1 Running 0 22s 10.0.22.162 ip-10-0-22-75.ap-northeast-1.compute.internal <none> <none>
whenUnsatisfiable: DoNotScheduleに変更し、再度3つのPodをapplyします。
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-deployment
spec:
(略)
template:
metadata:
labels:
name: my-deployment
app: my-deployment
spec:
(略)
topologySpreadConstraints:
- maxSkew: 1
topologyKey: kubernetes.io/hostname
whenUnsatisfiable: DoNotSchedule # 制約を見たせない場合はPodを起動しない
labelSelector:
matchLabels:
app: my-deployment
$ kubectl get pod -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES sre-external-dns-6df9778f89-mkc4v 1/1 Running 0 88s 10.0.22.33 ip-10-0-22-75.ap-northeast-1.compute.internal <none> <none> sre-my-deployment-9f4f64dcd-7qt2f 0/1 Pending 0 70s <none> <none> <none> <none> sre-my-deployment-9f4f64dcd-bnbjb 1/1 Running 0 87s 10.0.22.96 ip-10-0-22-75.ap-northeast-1.compute.internal <none> <none> sre-my-deployment-9f4f64dcd-zlg5l 1/1 Running 0 70s 10.0.21.169 ip-10-0-21-33.ap-northeast-1.compute.internal <none> <none>
sre-my-deployment-9f4f64dcd-7qt2fがPendingになりました。
Podのログを見てみます。
$ kubectl describe pod sre-my-deployment-9f4f64dcd-7qt2f (略) Events: Type Reason Age From Message ---- ------ ---- ---- ------- Warning FailedScheduling 2m19s (x2 over 2m20s) default-scheduler 0/3 nodes are available: 1 Insufficient cpu, 2 node(s) didn't match pod topology spread constraints.
NodeのCPUリソースが不足しているためtopologySpreadConstraintsの制約を満たせる配置先Nodeが無い、というWarningが出ています。
数秒後、topologySpreadConstraintsの制約を満たせるようにするために、ClusterAutoscalerによりNodeが追加されました。
Kubernetes内でClusterAutoscalerを実行している場合は、配置先Nodeが見つからなければNodeを追加してくれるようです。
ただしNodeが起動するまでの間PodはPendingのままになり、意図せずサービスダウンにつながる可能性があります。
$ kubectl describe pod sre-my-deployment-9f4f64dcd-7qt2f
(略)
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 2m19s (x2 over 2m20s) default-scheduler 0/3 nodes are available: 1 Insufficient cpu, 2 node(s) didn't match pod topology spread constraints.
Normal TriggeredScaleUp 2m17s cluster-autoscaler pod triggered scale-up: [{my-eks-cluster-wg01-20220201072317414200000009 3->4 (max: 10)}]
Warning FailedScheduling 41s (x3 over 71s) default-scheduler 0/4 nodes are available: 1 Insufficient cpu, 1 node(s) had taint {node.kubernetes.io/not-ready: }, that the pod didn't tolerate, 2 node(s) didn't match pod topology spread constraints.
Normal Scheduled 30s default-scheduler Successfully assigned my-namespace/sre-my-deployment-9f4f64dcd-7qt2f to ip-10-0-21-8.ap-northeast-1.compute.internal
Normal Pulling 28s kubelet Pulling image "wordpress:5.8.3"
Normal Pulled 12s kubelet Successfully pulled image "wordpress:5.8.3" in 16.245567381s
Normal Created 11s kubelet Created container my-deployment
Normal Started 11s kubelet Started container my-deployment
ここまでのまとめ
whenUnsatisfiable: ScheduleAnywayの場合、topologySpreadConstraintsの制約を満たせるようPod配置しようとする。起動中のNodeで制約を満たせない場合は制約に違反する形でPodを配置する。whenUnsatisfiable: DoNotScheduleの場合、topologySpreadConstraintsの制約を満たせるようPod配置しようとする。起動中のNodeで制約を満たせない場合はPodを起動せずPodがPending状態になる。その際ClusterAutoscalerによりAutoScalingが行われている環境であれば、制約を満たせるようにNodeを追加する。ただしNodeを追加するまでの間、PodのPending状態が続く。
2. Podの配置状態がPod Topology Spread Constraintsを満たさなくなったとき、DeschedulerによってPod Topology Spread Constraintsを満たすよう再配置されるか?
1.と同様にDeploymentを用意し、まずはtopologySpreadConstraintsに違反するようPodを配置します。
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-deployment
spec:
(略)
template:
metadata:
labels:
name: my-deployment
app: my-deployment
spec:
(略)
topologySpreadConstraints:
- maxSkew: 1
topologyKey: kubernetes.io/hostname
whenUnsatisfiable: ScheduleAnyway
labelSelector:
matchLabels:
app: my-deployment
$ kubectl get pod -n my-namespace -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES sre-external-dns-6df9778f89-zw584 1/1 Running 0 25m 10.0.22.114 ip-10-0-22-115.ap-northeast-1.compute.internal <none> <none> sre-my-deployment-6f5c64cd65-2xh4w 1/1 Running 0 25m 10.0.21.41 ip-10-0-21-8.ap-northeast-1.compute.internal <none> <none> sre-my-deployment-6f5c64cd65-cmpml 1/1 Running 0 25m 10.0.21.117 ip-10-0-21-8.ap-northeast-1.compute.internal <none> <none> sre-my-deployment-6f5c64cd65-f9bch 1/1 Running 0 25m 10.0.22.141 ip-10-0-22-75.ap-northeast-1.compute.internal <none> <none> sre-my-deployment-6f5c64cd65-mcm7x 1/1 Running 0 25m 10.0.22.84 ip-10-0-22-115.ap-northeast-1.compute.internal <none> <none> sre-my-deployment-6f5c64cd65-rqrbh 1/1 Running 0 14m 10.0.22.142 ip-10-0-22-115.ap-northeast-1.compute.internal <none> <none> sre-my-deployment-6f5c64cd65-vb2r8 1/1 Running 0 25m 10.0.22.163 ip-10-0-22-115.ap-northeast-1.compute.internal <none> <none>
maxSkew: 1としていますがip-10-0-22-115.ap-northeast-1.compute.internalで起動しているPodが3つ、ip-10-0-22-75.ap-northeast-1.compute.internalで起動しているPodが1つで差分が2になり、topologySpreadConstraintsに違反している状態です。
(whenUnsatisfiable: ScheduleAnywayとしているので違反していてもPodが起動します)
この状態でDeschedulerをapplyします。 Quick Startによると複数の使用方法があります。 今回はDeploymentを使います。
$ kubectl apply -f rbac.yml $ kubectl apply -f configmap.yml $ kubectl apply -f deployment.yml $ kubectl get pod -n kube-system | grep descheduler descheduler-7b6945c489-fldtg 1/1 Running 0 12m
Deschedulerでは、どのように再スケジューリングを行うかを定義するポリシーが2022/10時点で10種類あります。
各ポリシーの説明はリポジトリのREADMEを参照してください。
複数組み合わせて使用することも可能です。
今回はRemovePodsViolatingTopologySpreadConstraintのみを使用します。
Deschedulerのapply後、しばらく待ってDeschedulerのログとPodの状態を見てみます。
$ kubectl logs descheduler-7b6945c489-fldtg -n kube-system (略) I1014 00:59:43.397763 1 node.go:123] "Pod can possibly be scheduled on a different node" pod="my-namespace/sre-my-deployment-6f5c64cd65-cmpml" node="ip-10-0-22-115.ap-northeast-1.compute.internal" I1014 00:59:43.397800 1 node.go:123] "Pod can possibly be scheduled on a different node" pod="my-namespace/sre-my-deployment-6f5c64cd65-2xh4w" node="ip-10-0-22-115.ap-northeast-1.compute.internal" I1014 00:59:43.397813 1 node.go:123] "Pod can possibly be scheduled on a different node" pod="my-namespace/sre-my-deployment-6f5c64cd65-rqrbh" node="ip-10-0-21-8.ap-northeast-1.compute.internal" I1014 00:59:43.397821 1 node.go:123] "Pod can possibly be scheduled on a different node" pod="my-namespace/sre-my-deployment-6f5c64cd65-mcm7x" node="ip-10-0-21-8.ap-northeast-1.compute.internal" I1014 00:59:43.397829 1 node.go:123] "Pod can possibly be scheduled on a different node" pod="my-namespace/sre-my-deployment-6f5c64cd65-vb2r8" node="ip-10-0-21-8.ap-northeast-1.compute.internal" I1014 00:59:43.397837 1 node.go:123] "Pod can possibly be scheduled on a different node" pod="my-namespace/sre-my-deployment-6f5c64cd65-rqrbh" node="ip-10-0-21-8.ap-northeast-1.compute.internal" I1014 00:59:43.397854 1 node.go:123] "Pod can possibly be scheduled on a different node" pod="my-namespace/sre-my-deployment-6f5c64cd65-cmpml" node="ip-10-0-22-115.ap-northeast-1.compute.internal" I1014 00:59:43.397861 1 node.go:123] "Pod can possibly be scheduled on a different node" pod="my-namespace/sre-my-deployment-6f5c64cd65-2xh4w" node="ip-10-0-22-115.ap-northeast-1.compute.internal" I1014 00:59:43.397869 1 node.go:123] "Pod can possibly be scheduled on a different node" pod="my-namespace/sre-my-deployment-6f5c64cd65-rqrbh" node="ip-10-0-21-8.ap-northeast-1.compute.internal" I1014 00:59:43.397876 1 node.go:123] "Pod can possibly be scheduled on a different node" pod="my-namespace/sre-my-deployment-6f5c64cd65-mcm7x" node="ip-10-0-21-8.ap-northeast-1.compute.internal" I1014 00:59:43.397883 1 node.go:123] "Pod can possibly be scheduled on a different node" pod="my-namespace/sre-my-deployment-6f5c64cd65-vb2r8" node="ip-10-0-21-8.ap-northeast-1.compute.internal" I1014 00:59:43.397890 1 node.go:123] "Pod can possibly be scheduled on a different node" pod="my-namespace/sre-my-deployment-6f5c64cd65-rqrbh" node="ip-10-0-21-8.ap-northeast-1.compute.internal" I1014 00:59:43.397902 1 node.go:123] "Pod can possibly be scheduled on a different node" pod="my-namespace/sre-my-deployment-6f5c64cd65-cmpml" node="ip-10-0-22-115.ap-northeast-1.compute.internal" I1014 00:59:43.397909 1 node.go:123] "Pod can possibly be scheduled on a different node" pod="my-namespace/sre-my-deployment-6f5c64cd65-2xh4w" node="ip-10-0-22-115.ap-northeast-1.compute.internal" I1014 00:59:43.397916 1 node.go:123] "Pod can possibly be scheduled on a different node" pod="my-namespace/sre-my-deployment-6f5c64cd65-rqrbh" node="ip-10-0-21-8.ap-northeast-1.compute.internal" I1014 00:59:43.397927 1 node.go:123] "Pod can possibly be scheduled on a different node" pod="my-namespace/sre-my-deployment-6f5c64cd65-mcm7x" node="ip-10-0-21-8.ap-northeast-1.compute.internal" I1014 00:59:43.397934 1 node.go:123] "Pod can possibly be scheduled on a different node" pod="my-namespace/sre-my-deployment-6f5c64cd65-vb2r8" node="ip-10-0-21-8.ap-northeast-1.compute.internal" I1014 00:59:43.397940 1 node.go:123] "Pod can possibly be scheduled on a different node" pod="my-namespace/sre-my-deployment-6f5c64cd65-rqrbh" node="ip-10-0-21-8.ap-northeast-1.compute.internal" I1014 00:59:43.397953 1 node.go:123] "Pod can possibly be scheduled on a different node" pod="my-namespace/sre-my-deployment-6f5c64cd65-cmpml" node="ip-10-0-22-115.ap-northeast-1.compute.internal" I1014 00:59:43.397959 1 node.go:123] "Pod can possibly be scheduled on a different node" pod="my-namespace/sre-my-deployment-6f5c64cd65-2xh4w" node="ip-10-0-22-115.ap-northeast-1.compute.internal" I1014 00:59:43.397967 1 node.go:123] "Pod can possibly be scheduled on a different node" pod="my-namespace/sre-my-deployment-6f5c64cd65-rqrbh" node="ip-10-0-21-8.ap-northeast-1.compute.internal" I1014 00:59:43.397973 1 node.go:123] "Pod can possibly be scheduled on a different node" pod="my-namespace/sre-my-deployment-6f5c64cd65-mcm7x" node="ip-10-0-21-8.ap-northeast-1.compute.internal" I1014 00:59:43.397982 1 node.go:123] "Pod can possibly be scheduled on a different node" pod="my-namespace/sre-my-deployment-6f5c64cd65-vb2r8" node="ip-10-0-21-8.ap-northeast-1.compute.internal" I1014 00:59:43.397988 1 node.go:123] "Pod can possibly be scheduled on a different node" pod="my-namespace/sre-my-deployment-6f5c64cd65-rqrbh" node="ip-10-0-21-8.ap-northeast-1.compute.internal" I1014 00:59:43.398001 1 node.go:123] "Pod can possibly be scheduled on a different node" pod="my-namespace/sre-my-deployment-6f5c64cd65-cmpml" node="ip-10-0-22-115.ap-northeast-1.compute.internal" I1014 00:59:43.398010 1 node.go:123] "Pod can possibly be scheduled on a different node" pod="my-namespace/sre-my-deployment-6f5c64cd65-2xh4w" node="ip-10-0-22-115.ap-northeast-1.compute.internal" I1014 00:59:43.398016 1 node.go:123] "Pod can possibly be scheduled on a different node" pod="my-namespace/sre-my-deployment-6f5c64cd65-rqrbh" node="ip-10-0-21-8.ap-northeast-1.compute.internal" I1014 00:59:43.398023 1 node.go:123] "Pod can possibly be scheduled on a different node" pod="my-namespace/sre-my-deployment-6f5c64cd65-mcm7x" node="ip-10-0-21-8.ap-northeast-1.compute.internal" I1014 00:59:43.398030 1 node.go:123] "Pod can possibly be scheduled on a different node" pod="my-namespace/sre-my-deployment-6f5c64cd65-vb2r8" node="ip-10-0-21-8.ap-northeast-1.compute.internal" I1014 00:59:43.398036 1 node.go:123] "Pod can possibly be scheduled on a different node" pod="my-namespace/sre-my-deployment-6f5c64cd65-rqrbh" node="ip-10-0-21-8.ap-northeast-1.compute.internal" I1014 00:59:43.398057 1 node.go:123] "Pod can possibly be scheduled on a different node" pod="my-namespace/sre-my-deployment-6f5c64cd65-cmpml" node="ip-10-0-22-115.ap-northeast-1.compute.internal" I1014 00:59:43.398067 1 node.go:123] "Pod can possibly be scheduled on a different node" pod="my-namespace/sre-my-deployment-6f5c64cd65-2xh4w" node="ip-10-0-22-115.ap-northeast-1.compute.internal" I1014 00:59:43.398076 1 node.go:123] "Pod can possibly be scheduled on a different node" pod="my-namespace/sre-my-deployment-6f5c64cd65-rqrbh" node="ip-10-0-21-8.ap-northeast-1.compute.internal" I1014 00:59:43.398088 1 node.go:123] "Pod can possibly be scheduled on a different node" pod="my-namespace/sre-my-deployment-6f5c64cd65-mcm7x" node="ip-10-0-21-8.ap-northeast-1.compute.internal" I1014 00:59:43.398097 1 node.go:123] "Pod can possibly be scheduled on a different node" pod="my-namespace/sre-my-deployment-6f5c64cd65-vb2r8" node="ip-10-0-21-8.ap-northeast-1.compute.internal" I1014 00:59:43.398104 1 node.go:123] "Pod can possibly be scheduled on a different node" pod="my-namespace/sre-my-deployment-6f5c64cd65-rqrbh" node="ip-10-0-21-8.ap-northeast-1.compute.internal" (略) I1014 00:59:46.584512 1 node.go:123] "Pod can possibly be scheduled on a different node" pod="my-namespace/sre-my-deployment-6f5c64cd65-vb2r8" node="ip-10-0-21-8.ap-northeast-1.compute.internal" I1014 00:59:46.618871 1 evictions.go:160] "Evicted pod" pod="my-namespace/sre-my-deployment-6f5c64cd65-vb2r8" reason="PodTopologySpread" I1014 00:59:46.619252 1 descheduler.go:291] "Number of evicted pods" totalEvicted=1 I1014 00:59:46.619407 1 event.go:294] "Event occurred" object="my-namespace/sre-my-deployment-6f5c64cd65-vb2r8" kind="Pod" apiVersion="v1" type="Normal" reason="Descheduled" message="pod evicted by sigs.k8s.io/deschedulerPodTopologySpread" I1014 00:59:46.775915 1 request.go:597] Waited for 156.080779ms due to client-side throttling, not priority and fairness, request: POST:https://172.20.0.1:443/api/v1/namespaces/my-namespace/events
$ kubectl get pod -n my-namespace -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES sre-external-dns-6df9778f89-zw584 1/1 Running 0 40m 10.0.22.114 ip-10-0-22-115.ap-northeast-1.compute.internal <none> <none> sre-my-deployment-6f5c64cd65-2jljk 1/1 Running 0 3m4s 10.0.23.105 ip-10-0-23-182.ap-northeast-1.compute.internal <none> <none> sre-my-deployment-6f5c64cd65-2xh4w 1/1 Running 0 40m 10.0.21.41 ip-10-0-21-8.ap-northeast-1.compute.internal <none> <none> sre-my-deployment-6f5c64cd65-5kwds 1/1 Running 0 8m4s 10.0.23.94 ip-10-0-23-182.ap-northeast-1.compute.internal <none> <none> sre-my-deployment-6f5c64cd65-cmpml 1/1 Running 0 40m 10.0.21.117 ip-10-0-21-8.ap-northeast-1.compute.internal <none> <none> sre-my-deployment-6f5c64cd65-j7j8s 1/1 Running 0 13m 10.0.22.126 ip-10-0-22-115.ap-northeast-1.compute.internal <none> <none> sre-my-deployment-6f5c64cd65-rblqw 1/1 Running 0 3m4s 10.0.23.212 ip-10-0-23-182.ap-northeast-1.compute.internal <none> <none>
ip-10-0-22-115.ap-northeast-1.compute.internal のNodeで起動していたPodがevict対象となり、Podの再配置が行われました。((ただしwhenUnsatisfiable: ScheduleAnywayとしているため、再配置後も ip-10-0-23-182.ap-northeast-1.compute.internal にPodが偏ってしまいました。このことからDeschedulerによるevict対象の判定と、kube-schedulerによる再スケジューリングの判定が別々に行われていることが分かります。 ))
3. PodDisruptionBudgetを指定することで、Deschedulerによる再配置が行われている間のサービスダウンを防止できるか?
Deschedulerにより意図せずPodが全て落ちてサービスダウンが発生することを防ぐため、PodDisruptionBudgetを設定します。 DescheduleがPodDisruptionBudgetに従ってPodをevictするか検証します。
まず1. と2. と同様にDeploymentを用意し、topologySpreadConstraintsに違反するようPodを配置します。
$ kubectl get pod -n my-namespace -n kube-system NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES sre-external-dns-6df9778f89-zw584 1/1 Running 0 7h39m 10.0.22.114 ip-10-0-22-115.ap-northeast-1.compute.internal <none> <none> sre-my-deployment-6f5c64cd65-4rpv7 1/1 Running 0 2m2s 10.0.21.68 ip-10-0-21-8.ap-northeast-1.compute.internal <none> <none> sre-my-deployment-6f5c64cd65-64qrt 1/1 Running 0 2m2s 10.0.21.27 ip-10-0-21-8.ap-northeast-1.compute.internal <none> <none> sre-my-deployment-6f5c64cd65-6lzns 1/1 Running 0 2m2s 10.0.22.142 ip-10-0-22-115.ap-northeast-1.compute.internal <none> <none> sre-my-deployment-6f5c64cd65-j7j8s 1/1 Running 0 7h12m 10.0.22.126 ip-10-0-22-115.ap-northeast-1.compute.internal <none> <none> sre-my-deployment-6f5c64cd65-t7lmc 1/1 Running 0 2m2s 10.0.22.204 ip-10-0-22-115.ap-northeast-1.compute.internal <none> <none> sre-my-deployment-6f5c64cd65-vfmd7 1/1 Running 0 2m2s 10.0.22.125 ip-10-0-22-75.ap-northeast-1.compute.internal <none> <none>
maxSkew: 1としていますがip-10-0-22-115.ap-northeast-1.compute.internalで起動しているPodが3つ、ip-10-0-22-75.ap-northeast-1.compute.internalで起動しているPodが1つで差分が2になり、topologySpreadConstraintsに違反している状態です。
(whenUnsatisfiable: ScheduleAnywayとしているので違反していてもPodが起動します)
PodDisruptionBudgetを作成します。
「app: my-deploymentのLabelを持つPodを少なくとも6つ起動しておく」設定にします。
---
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: my-deployment
spec:
minAvailable: 6
selector:
matchLabels:
app: my-deployment
Deschedulerがip-10-0-22-115.ap-northeast-1.compute.internalで起動しているいずれかのPodをevictしようとしてもPodDisruptionBudgetに違反する(evictするとPodの起動数が5になり、最低起動数6に違反する)ためevictされない、が期待する動作です。
しばらく待ってDeschedulerのログとPodの状態を見てみます。
$ kubectl logs descheduler-5478dfd978-szwj6 -n kube-system (略) I1014 08:38:25.339509 1 node.go:123] "Pod can possibly be scheduled on a different node" pod="my-namespace/sre-my-deployment-6f5c64cd65-z8qgx" node="ip-10-0-21-8.ap-northeast-1.compute.internal" E1014 08:38:25.350719 1 evictions.go:143] "Error evicting pod" err="error when evicting pod (ignoring) \"sre-my-deployment-6f5c64cd65-z8qgx\": Cannot evict pod as it would violate the pod's disruption budget." pod="my-namespace/sre-my-deployment-6f5c64cd65-z8qgx" reason="PodTopologySpread" I1014 08:38:25.350756 1 descheduler.go:291] "Number of evicted pods" totalEvicted=0 (略)
$ kubectl get pod -n my-namespace -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES sre-external-dns-6df9778f89-zw584 1/1 Running 0 8h 10.0.22.114 ip-10-0-22-115.ap-northeast-1.compute.internal <none> <none> sre-my-deployment-6f5c64cd65-5ts48 1/1 Running 0 28m 10.0.21.117 ip-10-0-21-8.ap-northeast-1.compute.internal <none> <none> sre-my-deployment-6f5c64cd65-czdbp 1/1 Running 0 29m 10.0.22.141 ip-10-0-22-75.ap-northeast-1.compute.internal <none> <none> sre-my-deployment-6f5c64cd65-n4s6r 1/1 Running 0 28m 10.0.22.84 ip-10-0-22-115.ap-northeast-1.compute.internal <none> <none> sre-my-deployment-6f5c64cd65-qmjmx 1/1 Running 0 28m 10.0.22.142 ip-10-0-22-115.ap-northeast-1.compute.internal <none> <none> sre-my-deployment-6f5c64cd65-xtwwr 1/1 Running 0 28m 10.0.21.41 ip-10-0-21-8.ap-northeast-1.compute.internal <none> <none> sre-my-deployment-6f5c64cd65-z8qgx 1/1 Running 0 28m 10.0.22.163 ip-10-0-22-115.ap-northeast-1.compute.internal <none> <none>
Deschedulerがsre-my-deployment-6f5c64cd65-z8qgxをevict可能と判断しましたが、その後sre-my-deployment-6f5c64cd65-z8qgxをevictするとPodDisruptionBudgetに違反するというエラーが出ています。
Podはevictされず、元々起動していたNodeと同じNodeで引き続き起動しています。
$ kubectl get pod -n my-namespace -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES sre-external-dns-6df9778f89-zw584 1/1 Running 0 8h 10.0.22.114 ip-10-0-22-115.ap-northeast-1.compute.internal <none> <none> sre-my-deployment-6f5c64cd65-5ts48 1/1 Running 0 36m 10.0.21.117 ip-10-0-21-8.ap-northeast-1.compute.internal <none> <none> sre-my-deployment-6f5c64cd65-czdbp 1/1 Running 0 37m 10.0.22.141 ip-10-0-22-75.ap-northeast-1.compute.internal <none> <none> sre-my-deployment-6f5c64cd65-n4s6r 1/1 Running 0 36m 10.0.22.84 ip-10-0-22-115.ap-northeast-1.compute.internal <none> <none> sre-my-deployment-6f5c64cd65-qmjmx 1/1 Running 0 36m 10.0.22.142 ip-10-0-22-115.ap-northeast-1.compute.internal <none> <none> sre-my-deployment-6f5c64cd65-xtwwr 1/1 Running 0 36m 10.0.21.41 ip-10-0-21-8.ap-northeast-1.compute.internal <none> <none> sre-my-deployment-6f5c64cd65-z8qgx 1/1 Running 0 36m 10.0.22.163 ip-10-0-22-115.ap-northeast-1.compute.internal <none> <none>
PodDisruptionBudgetを削除すると再配置が行われました。
$ kubectl get pod -n my-namespace -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES sre-external-dns-6df9778f89-zw584 1/1 Running 0 8h 10.0.22.114 ip-10-0-22-115.ap-northeast-1.compute.internal <none> <none> sre-my-deployment-6f5c64cd65-9b2vs 1/1 Running 1 3m21s 10.0.23.155 ip-10-0-23-93.ap-northeast-1.compute.internal <none> <none> sre-my-deployment-6f5c64cd65-bwjwf 1/1 Running 0 3m21s 10.0.21.236 ip-10-0-21-8.ap-northeast-1.compute.internal <none> <none> sre-my-deployment-6f5c64cd65-czdbp 1/1 Running 0 41m 10.0.22.141 ip-10-0-22-75.ap-northeast-1.compute.internal <none> <none> sre-my-deployment-6f5c64cd65-dcv46 1/1 Running 1 3m21s 10.0.21.68 ip-10-0-21-8.ap-northeast-1.compute.internal <none> <none> sre-my-deployment-6f5c64cd65-lq762 1/1 Running 0 3m21s 10.0.23.20 ip-10-0-23-93.ap-northeast-1.compute.internal <none> <none> sre-my-deployment-6f5c64cd65-n85pb 1/1 Running 0 3m21s 10.0.22.204 ip-10-0-22-115.ap-northeast-1.compute.internal <none> <none>
まとめ
本記事ではPod Topology Spread Constraints, Descheduler, PodDisruptionBudgetを用いてPodを配置するNodeを分散する方法をご紹介しました。
記事内ではtopologyKey: kubernetes.io/hostnameとしていましたが、AZ障害に備えてAZを分散したり、アプリケーションの要件に応じて独自のLabelを用いて分散したり等、様々なユースケースで活用できそうです。
